小羚和安迪説,我大概是明白資料中心的組成了,你能不能再多說說vSAN是怎麼儲存資料呢?他是如何能把我的重要檔案自動備份又能同時取用呢?
安迪說,當然沒問題!儲存是一個很大的領域,我們只能先從最基本的基礎開始,我會先從三個資料儲存系統 - 區塊儲存系統、檔案儲存系統和物件儲存系統說起,這裡說的系統都是軟體層面上的邏輯,不會深入探討到硬碟。
Block storage是最基本的儲存系統,所以讓我們從這裡開始
資料在電腦裡是以1和0儲存在某個"介質"上面,例如機械式硬碟(HDD)利用磁性,而固態硬碟(SSD)利用電子,也有用光的CD,而Block storage簡單來說就是我們能看到的一塊塊的硬碟和儲存裝置,我們把儲存裝置與我們的電腦連接,我們的電腦透過Block storage的API對裡面的資料進行增刪改查。
接下來,我們有了作業系統,作業系統他方便了我們把資料存進去Block storage裝置,可以說,作業系統是上層應用與Block storage裝置溝通的橋樑,那麼回答一個問題,作業系統是如何與硬碟打交道呢?
首先,作業系統利用LUN ID識別硬碟,LUN是一個或一組或半個硬碟的邏輯代號,為何有半個呢?
例如我們的windows有一個硬碟,把他分成C槽和D槽,那麼他們就是各半個,LUN他不是獨佔式的,也就是說多台主機能共享一個儲存設備,不過一般不會這麼用,因為Block storage的資料隔離沒有做得這麼好,若是同時寫入資料容易被混淆。
那麼block的由來是什麼呢?從作業系統的角度,資料的讀取和寫入都是以block為最小單位,一個block是一段固定長度的bytes,常見為4096 bytes,這樣的設定的用意是提升資料讀寫的速度,如果一個個byte寫,一來一往速度非常慢。
對於HDD來說,連續讀寫可以大幅提升I/O速度,然而我們的資料會需要經常性的寫入和刪除,例如我們寫了十筆連續的Block,過一段時間,想把第五個Block資料給刪除,這樣中間就會有空餘的浪費,這樣該怎麼辦呢?
如果我們時常要求連續讀寫,會造成巨大的資源浪費,所以上層的作業系統會利用Linked-List資料結構把碎片化的Block記錄下來,把整段資料拼湊出來
一個block對應一個或多個硬體的扇區(sector),常見的一個sector大小為512 bytes,所以block是給作業系統看的邏輯地址,sector是Block storage上的實體地址。Block大小可以透過作業系統設定,查詢藉由指令stat /boot/ |grep "IO Block" 查詢
#> stat /boot/ |grep "IO Block"
Size: 4096 Blocks: 8 IO Block: 4096 directory
sector是Block storage上的實體地址,他也是把多個bytes分組成一個sector,我們拿機械式硬碟HDD舉例,HDD有個針頭會去掃描磁碟,掃描的部分就是一個個扇區,如下圖所示
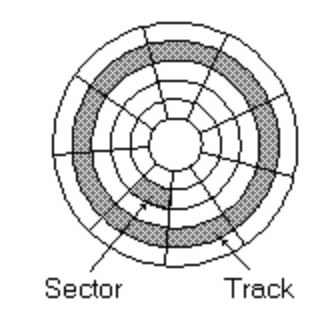
HDD就是用類似光碟的圓盤一個個堆疊出來了,剛剛提到的"扇區"就是上圖的sector,代表同個半徑下一小塊長度
最後總結一下Block storage有什麼優缺點
Block storage最大的優點就是他使得計算與儲存分離,我們能輕易地透過LUN ID外接一個硬碟或硬碟組
高性能:
IOPS(Inputs Outputs per Seconds)高,延遲低,適合用作公司的database server或數據中心
易於修改:
如果想改變block裡的一個小部分資料,直接改那個block就可以,如果是檔案系統或object system,需要整個檔案或object都改
擴充容易
擴充非常簡單,一個LUN ID就可以接上系統了,適合用在SAN(儲存區域網路)裡
不能同時讀寫
不能多台機器同時讀寫同一塊硬碟,雖然可以透過軟體解決此問題但是會造成性能下降
Metadata
Block storage沒有什麼Metadata,File system有檔案路徑、名字、大小等等快速定位資料,Block storage只有地址起始位置(LBA)、長度
有了File storage,就能方便我們寫程式去操作資料!
如果要和硬碟直接打交道,Block storage是唯一的方式,只是對人非常不友好,我怎麼知道我的資料的Block存在哪裏?是連續的存呢?還是分散的存?如果每筆資料都連續的存,那肯定對硬碟的利用率不友好,如果是分散存,需要一個Linked-List資料結構去紀錄。
任何資訊界的難題只需要加一層就可以解決,如果不行,那就兩層,所以我們就加個一層吧!為了讓使用者能夠輕鬆的操作儲存資料,作業系統在Block storage上面加了一層File system。
我們平常用的Windows為了讓使用者方便存取資料,就是使用File system,這大家應該很熟悉,用滑鼠鍵盤敲一敲點一點就可以對檔案進行存取,由於File system就是Block storage上面加一層,所以檔案的內容都是存在一個個的block中
除了檔案的內容之外,檔案的metadata比如創建時間、權限、大小等等也需要存在另一個地方,專門存這些文件metadata的地方就叫做inode。
一個檔案的inode可以透過stat來查詢
#> stat demo.txt
File: ‘demo.txt’
Size: 12 Blocks: 8 IO Block: 4096 regular file
Device: fd02h/64770d Inode: 238749826 Links: 1
Access: (0644/-rw-r--r--) Uid: (51426876/ ckaijia) Gid: ( 201/ mts)
Access: 2021-08-28 07:27:02.001795167 -0700
Modify: 2021-08-28 07:27:02.001795167 -0700
Change: 2021-08-28 07:27:02.001795167 -0700
Birth: -
inode也會消耗儲存空間,所以格式化硬碟的時候,作業系統會將硬碟分成兩個區域,一個存資料,一個存inode,並且指定inode分區的大小,所以就算檔案很小,一塊硬碟裡還是有檔案數量的限制
首先,不是透過檔案名字,檔案名字只是讓使用者方便識別,作業系統透過inode ID,每個inode都有一個號碼,例如上面的demo.txt就是238749826,根據使用者點開的文件找到inode號碼。
第二,根據inode號碼去資料分區根據inode找到對應的data。
最後,根據indoe的data,找到檔案裡的資料存在哪個block。
File system最大的優點就是他對人類友好,有目錄結構、好記得名字等等,方便UI呈現,除此之外還有如下優點
方便共享
一個inode就能與其他同台電腦上的user直接分享檔案,而且有權限控制
安全
如上述所示,Linux有三種權限控制 - 自己、組和其他
成本低
不需要昂貴的光纖,只要買機器,接上外接硬碟,透過作業系統上的File system,就可以使用
資料讀寫慢
因為讀取跟寫入都有兩層,除了讀寫本身資料(Block storage)之外,還有inode裡的metadata需要處理
難以遷移
如過想把文件都搬遷到另一個作業系統有點困難,如果file storage的格式不同或inode的演算法不同就更糟了
權限控制
權限控制只有三層 - 自己、group、others,無法滿足更複雜的需求
Object Storage - 雲端系統上最流行的儲存方式
Object storage和File storage一樣,是基於Block storage的,首先,與File storage方式不同,File storage就像是一棵樹,從點進去一個資料夾開始,裡面有很多檔案(葉子),也有資料夾(樹枝),再點進去資料夾,又會有檔案、資料夾,是一個樹狀結構,Object storage是扁平化結構,可以理解為所有檔案都存在一個資料夾裡,包括Object的metadata,且資料夾裡不會有資料夾,Object就是一個檔案,也可以是多個檔案的非結構化組合,所以Object storage沒有inode這種方式變得更容易索引和訪問。
Object storage的Metadata就像是File system的inode,用作索引對應的data位置,Object storage可以隨意定義自己的metadata資料結構,幫助快速檢索目標object,甚至是分散在不同主機的data。
綜上所述,Object storage非常適合存靜態不常使用的大數據,例如大量的影片、音樂等等,為使用者提供大量、安全、低成本的資料儲存服務。
從high level講,也就是使用方式講,Object storage主要是透過http API對資料進行增刪改查,與File systemAPI和Block storage的SCSI不同,Object storage更加方便各個語言的使用。這些Object實際上可以是任何類型的資料:PDF、影片、音檔、文本、網站資料或任何其他檔案類型。
正因為他的扁平化架構,他天生就適合作為分散式儲存的儲存方式,為何這麼說呢?首先,分散式儲存必須要資料分散且「容易」伸縮,由於是扁平化架構,我們容易把object切塊平均分散在不同機器,伸縮也非常方便,加了一台機器,等於對這個「資料夾」加大了空間。
加了機器除了可以提升儲存空間之外,還能提升資料的「可靠性」,例如一個object,我可以複製兩份,這樣我們可以說他的空間使用率是200%,保護力是1,因為他容許一台機器掛掉資料還在,雖然這種保護方法直觀簡單,但是現在各大雲端廠商為了節省成本,透過一些奇偶校驗法會使用例如RAID-5這種空間使用率只要150%,但是保護力也有1。
方便擴增
由於Object storage是扁平化架構,只要增加機器就是增加這個大平面的面積,不需要額外修改架構
成本低
公有雲端上的Object storage都特別便宜,例如Amazon S3
API 簡單
單純的使用HTTP進行增刪改查,進而支持長距離使用,例如你在台灣可以使用位在美國的Amazon S3儲存服務
不能修改
由於最小單位就是一個Object,所以想要修改一個Object代表需要上傳一個新的Object替換他,而File system還能在末尾增加一行資料
無法和database整合
傳統的database是結構化數據,例如SQL, Mysql等等,而object storage存放的主要是非結構化數據,且object storage的讀寫慢
無法與一般作業系統整合
因為一般的作業系統都是File system,下載一個object就像是下載一個檔案

